IdentifyParalogousLoci - Identify paralogous loci in a schema
Description
The IdentifyParalogousLoci module identifies paralogous loci, which are genes that have evolved by duplication within a genome and may have similar but not identical functions. Deciding what to do at an early stage of schema development will avoid potential problems in later stages when a schema is being actively used to classify strains. Merging highly similar loci occurring infrequently together and reported as paralogous into a single locus makes schemas more concise and may better reflect the functional similarity of the genes. However, if loci reported as paralogs are found mostly in the same genomes, excluding those loci from the schema may be advisable since the allele calling process may be unable to distinguish the two loci and therefore to unambiguously assign the alleles to the correct locus.
The IdentifyParalogousLoci module identifies paralogous loci through alignment with BLAST and a set of filtering criteria used to decide if loci should be considered paralogs. The groups of paralogous loci are written to an output file as a set of “Join” recommendations”Join”. These recommendations should be reviewed by the users to decide on the actual action to be performed.
Features
Identification of paralogous loci in a schema.
Optional annotation of the final recommendations.
Configurable parameters for the identification of paralogous loci.
Support for parallel processing using multiple CPUs.
Option to skip intermediate file cleanup after running the module.
Dependencies
BLAST (manual here)
Usage
The IdentifyParalogousLoci module can be used as follows:
SR IdentifyParalogousLoci -s /path/to/schema -o /path/to/output -c 4 -b 0.6 -tt 11 -st 0.2 -pm reps_vs_reps --nocleanup
Command-Line Arguments
-s, --schema-directory
(Required) Folder that contains the schema to identify paralogous loci.
-o, --output-directory
(Required) Path to the directory to which files will be stored.
-ann, --annotations
(Optional) Path to the tsv file with the schema annotations to be added to the recommendations file.
This file needs to have one column with loci with the same IDs as the ones in the schema.
-c, --cpu
(Optional) Number of CPUs to run BLAST instances.
Default: 1
-b, --bsr
(Optional) BSR value to consider alleles as the same locus.
Default: 0.6
-tt, --translation-table
(Optional) Translation table to use for the CDS translation.
Default: 11
-st, --size-threshold
(Optional) Size threshold to consider two paralogous loci as similar.
Default: 0.2
-pm, --processing-mode
(Optional) Mode to run the module.
Choices: reps_vs_reps, reps_vs_alleles, alleles_vs_alleles, alleles_vs_reps.
Default: alleles_vs_alleles
--nocleanup
(Optional) Flag to indicate whether to skip cleanup after running the module.
--debug
(Optional) Flag to indicate whether to run the module in debug mode.
Default: False
--logger
(Optional) Path to the logger file.
Default: None
Note
Always verify it the translation table (argument -tt) being used is the correct one for the species.
Algorithm Explanation
Algorithm to identify paralogous loci in a schema is shown below:
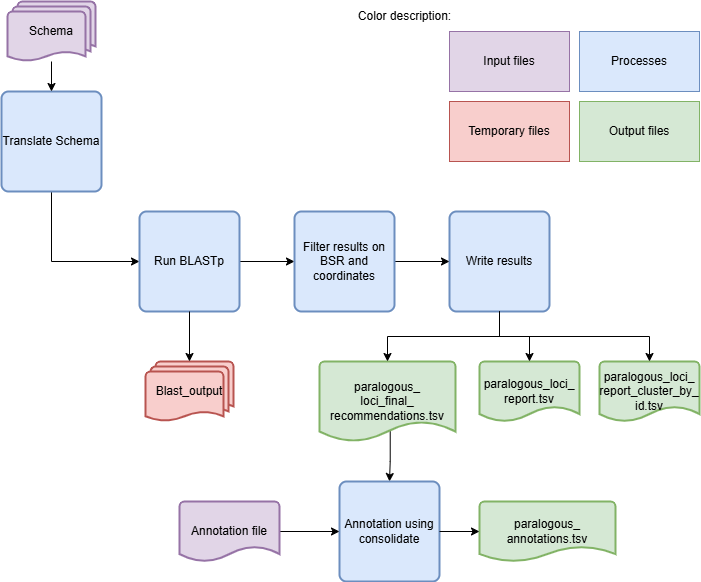
The IdentifyParalogousLoci module aligns the translated sequences of the loci using BLASTp. The BLASTp results are then filtered based on a BSR and sequence size thresholds. The coordinates of the loci are also checked to see if they intersect or are within a close distance.
The BLAST output is a TSV file, created by selecting BLAST’s output format 6 with the following columns:
qseqid sseqid qlen slen qstart qend sstart send length score gaps pident
The loci that were found to match and intercept or are in close proximity are grouped as potential paralogous loci and recommended to be merged into a single locus. It is advised to add loci annotations to the recommendations by passing a file with loci annotations to the –annotations parameter. Adding annotations can facilitate the decision process by easily checking if the annotations within groups of loci are similar, which may indicate that the loci have the same or similar functions. If there is a locus that should not be merged, the recommendation should be changed to Add. The annotation option will use the consolidate mode from the SchemaAnnotation module, so the input format should comform with the rules set in the SchemaAnnotation documentation.
Outputs
The directory structure of the output directory created by the IdentifyParalogousLoci module is shown below.
OutputFolderName
├── Blast # --nocleanup
│ ├── Blast_db_prot
│ │ ├── Blast_db_protein.pdb
│ │ ├── Blast_db_protein.phr
│ │ ├── Blast_db_protein.pin
│ │ ├── Blast_db_protein.pog
│ │ ├── Blast_db_protein.pos
│ │ ├── Blast_db_protein.pot
│ │ ├── Blast_db_protein.psq
│ │ ├── Blast_db_protein.ptf
│ │ └── Blast_db_protein.pto
│ ├── Blast_output
│ │ ├── blast_results_x.tsv
│ │ ├── blast_results_y.tsv
│ │ ├── blast_results_z.tsv
│ │ └── ...
│ ├── master_file.fasta
│ ├── self_score_folder
│ │ ├── blast_results_x.tsv
│ │ ├── blast_results_y.tsv
│ │ ├── blast_results_z.tsv
│ │ └── ...
│ └── Translation
│ ├── x_translation.fasta
│ ├── y_translation.fasta
│ ├── z_translation.fasta
│ └── ...
├── paralogous_annotations.tsv #-ann
├── paralogous_loci_report.tsv
├── paralogous_loci_report_cluster_by_id.tsv
└── paralogous_loci_final_recommendations.tsv
Report files description
Query_loci_id |
Subject_loci_id |
BSR |
if_loci_intersect |
if_close_distance |
Loci_min_allele_size |
Loci_max_allele_size |
Loci_mode_allele_size |
Loci_mean_allele_size |
|---|---|---|---|---|---|---|---|---|
x |
a |
0.7360028348688873 |
False |
False |
416.0|1349.0 |
544.0|1645.0 |
515.0|1628.0 |
476.75|1615.125 |
x |
b |
0.6146651702207258 |
False |
True |
416.0|599.0 |
544.0|738.0 |
515.0|738.0 |
476.75|720.625 |
x |
c |
0.6523642732049036 |
True |
True |
416.0|466.0 |
544.0|547.0 |
515.0|547.0 |
476.75|512.5714285714286 |
… |
This is an intermediate file that includes summary statistics for each locus used in the filtering process to identify potential paralogous loci. Not every match found in this file will be in the final recommendations file. Only those with the value TRUE in the columns if_loci_intersect and/or if_close distance will be grouped.
Columns description:
Query_loci_id: The locus ID of the query.
Subject_loci_id: The locus ID of the subject.
BSR: The BSR value between the query and subject loci.
if_loci_intersect: If the loci intersect.
if_close_distance: If the loci are close in distance.
Loci_min_allele_size: The minimum allele size of the loci, query and subject values are separated by '|'.
Loci_max_allele_size: The maximum allele size of the loci, query and subject values are separated by '|'.
Loci_mode_allele_size: The mode allele size of the loci, query and subject values are separated by '|'.
Loci_mean_allele_size: The mean allele size of the loci, query and subject values are separated by '|'.
Joined_loci_id |
Clustered_loci_ids |
|---|---|
x |
x,a,b,c |
y |
y,d,e,f |
z |
z,g,h |
… |
This file shows the identified groups of similar loci. The groups in this file do not necessarily match the groups of loci added to the final output file with the groups of potential paralogous loci. Loci in this file are only added to the final output file if they pass all the thresholds of intersection or closeness.
Columns description:
Joined_loci_id: First Locus on the cluster.
Clustered_loci_ids: List of all the loci that should be joined together.
Locus |
Action |
|---|---|
x |
Join |
y |
Join |
z |
Join |
# |
|
a |
Join |
b |
Join |
# |
|
… |
This is the main output file. The groups reported in this file have passed all the filtering criteria and are therefore recognized as potential paraloguos loci. It is recommended to add annotations to this file through the –annotations parameter and check the annotations in order to confirm if the groups make sense from a functional perspective.
Columns description:
Locus: Name of the locus to be joined in the clustered.
Action: Action to be taken, always 'Join' in this module.
#: Separates each cluster of loci.
Note
This file can be used as input for the CreateSchemaStructure module.
Loci |
Action |
Locus_annotation |
Annotation |
|---|---|---|---|
x |
Join |
x |
annotation |
y |
Join |
y |
annotation |
z |
Join |
z |
annotation |
# |
|||
a |
Join |
a |
annotation |
b |
Join |
b |
annotation |
# |
|||
… |
Columns description:
Loci: Name of the locus to be joined in the clustered.
Action: Action to be taken, always 'Join' in this module.
Locus_annotation: Name of the Locus in the annotation file (should be the same as Locus).
Annotation: Column with annotation from the annotation file.
Important
The name and number of columns with annotations depends on the structure of the file with annotations. The groups of paralogous loci are separated by #.
Examples
Here are some example commands to use the IdentifyParalogousLoci module:
# Identify paralogous loci using default parameters
SR IdentifyParalogousLoci -s /path/to/schema -o /path/to/output
# Identify paralogous loci with custom parameters
SR IdentifyParalogousLoci -s /path/to/schema -o /path/to/output -ann /path/to/annotation/file -c 4 -b 0.7 -tt 4 -st 0.3 -pm reps_vs_reps --nocleanup
Troubleshooting
If you encounter issues while using the IdentifyParalogousLoci module, consider the following troubleshooting tips:
Verify that the paths to the schema and output directories are correct.
Check the output directory for any error logs or messages.
Increase the number of CPUs using the -c or –cpu option if the process is slow.
If it is a BLAST database related error, try deleting the BLAST folders in the output and run the command again and run the schema through the AdaptLoci as it checks for loci name conflicts.