MatchSchemas - Match schemas in a directory
Description
The MatchSchemas module aligns the alleles of loci in two schemas to find loci common to both schemas. The module can be used to compare different schema versions for the same species, allowing to compare both vesions and update one of the versions based on the annotation data of the otehr schema.
Features
Configurable parameters for the matching process.
Optional annotation of the final matches.
Support for parallel processing using multiple CPUs.
Option to skip cleanup after running the module.
Dependencies
BLAST (manual here)
Usage
The MatchSchemas module can be used as follows:
SR MatchSchema -fs /path/to/first_schema -ss /path/to/second_schema -o /path/to/output_folder -c 6 -b 0.5 --nocleanup
Command-Line Arguments
-fs, --first-schema-directory
(Required) Folder that contains the first schema to identify paralogous loci.
-ss, --second-schema-directory
(Required) Folder that contains the second schema to identify paralogous loci.
-o, --output-directory
(Required) Path to the directory to which files will be stored.
-c, --cpu
(Optional) Number of CPUs to run BLAST instances.
Default: 1
-b, --bsr
(Optional) BSR value to consider alleles as the same locus.
Default: 0.6
-tt, --translation-table
(Optional) Translation table to use for the CDS translation.
Default: 11
-ra, --rep-vs-alleles
(Optional) If True then after the rep vs rep Blast the program will run a second Blast with rep vs alleles.
Default: False
--nocleanup
(Optional) Flag to indicate whether to skip cleanup after running the module.
--debug
(Optional) Flag to indicate whether to run the module in debug mode.
Default: False
--logger
(Optional) Path to the logger file.
Default: None
Note
Always verify it the translation table (argument -tt) being used is the correct one for the species.
Note
The –rep_vs_alleles mode is a more indept comparison. It takes longer to process, however the number of extra matches found is small. Should be used as an extra and more detailed comparison.
Algorithm Explanation
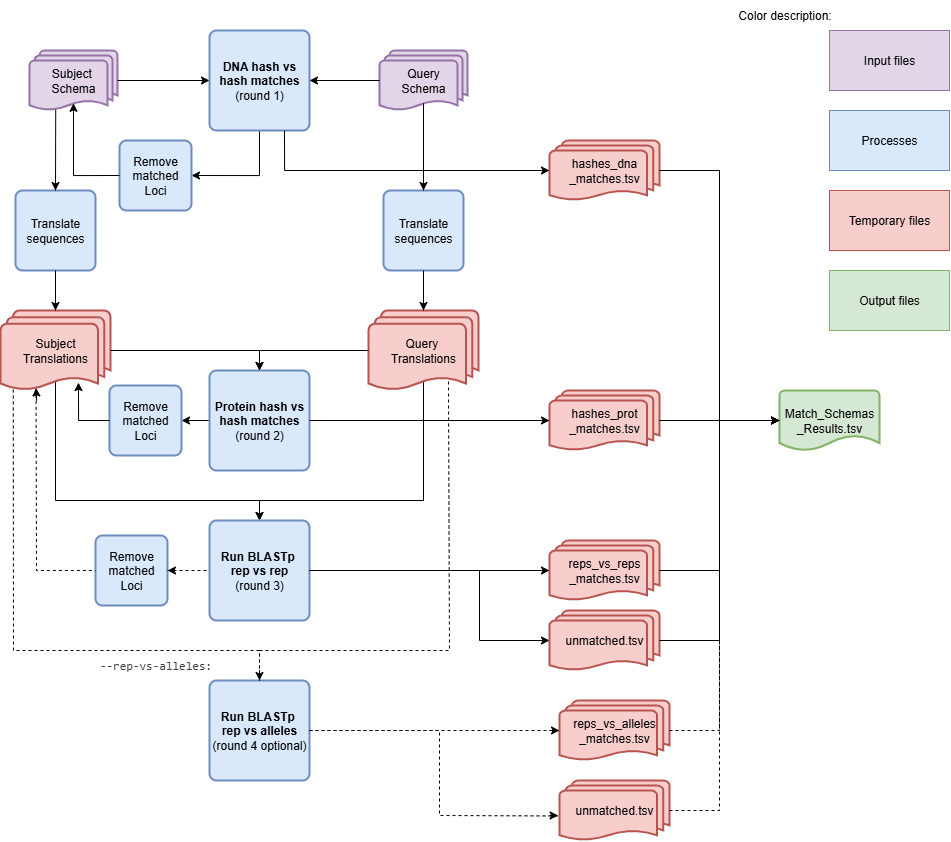
MatchSchemas Algorithm Flowchart:
Important
The module assigns the designation of Query to the schema with higher allele density (i.e. the average number of alleles per locus) and of Subject to the other schema. The input schemas should use the format used by the schemas created with chewBBACA.
- The module goes through three matching processes and a fourth optional one.
Comparison of DNA hashes.
Comparison of protein hashes.
Alignment between the representative alleles of both schemas with BLASTp.
(Optional) Alignment between the representative alleles of one schema and all alleles of the other schema with BLASTp.
The compariosn of DNA hashes is the less flexible method. The loci need to have an exact matches at the nucleotide sequence level in order to find matches. The comparison of protein hashes identifies loci which may not share alleles but with matching translated alleles (i.e. some translated alleles match because different codons can encode the same amino acid). The BLASTp comparison is the most sensitive method.
The BLAST output file has the following columns:
qseqid sseqid qlen slen qstart qend sstart send length score gaps pident
The BLAST matches are filtered based on the defined BSR value. The BSR threshold can be set through the –bsr parameter.
Each matching process is followed by a process where the loci that were matched are written to the main output file. The loci from the subject schema that have no matches transition into the next matching step. After the final matching step, the loci without matches are added to the output file with the corresponding Query or Subject as Not Matched.
Outputs
The directory structure of the output directory created by the MatchSchemas module is shown below.
OutputFolderName
├── blast_processing # --nocleanup
│ ├── subject_reps_vs_reps_blastdb
│ │ ├── subject_reps_vs_reps_blastdb.pdb
│ │ ├── subject_reps_vs_reps_blastdb.phr
│ │ ├── subject_reps_vs_reps_blastdb.pin
│ │ ├── subject_reps_vs_reps_blastdb.pog
│ │ ├── subject_reps_vs_reps_blastdb.pos
│ │ ├── subject_reps_vs_reps_blastdb.pot
│ │ ├── subject_reps_vs_reps_blastdb.psq
│ │ ├── subject_reps_vs_reps_blastdb.ptf
│ │ └── subject_reps_vs_reps_blastdb.pto
│ ├── subject_reps_vs_alleles_blastdb
│ │ ├── subject_reps_vs_alleles_blastdb.pdb
│ │ ├── subject_reps_vs_alleles_blastdb.phr
│ │ ├── subject_reps_vs_alleles_blastdb.pin
│ │ ├── subject_reps_vs_alleles_blastdb.pog
│ │ ├── subject_reps_vs_alleles_blastdb.pos
│ │ ├── subject_reps_vs_alleles_blastdb.pot
│ │ ├── subject_reps_vs_alleles_blastdb.psq
│ │ ├── subject_reps_vs_alleles_blastdb.ptf
│ │ └── subject_reps_vs_alleles_blastdb.pto
│ ├── blastp_results
│ │ ├── blast_results_x.tsv
│ │ ├── blast_results_y.tsv
│ │ ├── blast_results_z.tsv
│ │ └── ...
│ ├── Query_Translation
│ │ ├── x_translation.fasta
│ │ ├── y_translation.fasta
│ │ ├── z_translation.fasta
│ │ └── ...
| ├── Query_Translation_Rep
│ │ ├── x_rep_translation.fasta
│ │ ├── y_rep_translation.fasta
│ │ ├── z_rep_translation.fasta
│ │ └── ...
│ ├── Subject_Translation
│ │ ├── x_translation.fasta
│ │ ├── y_translation.fasta
│ │ ├── z_translation.fasta
│ │ └── ...
| ├── Subject_Translation_Rep
│ │ ├── x_rep_translation.fasta
│ │ ├── y_rep_translation.fasta
│ │ ├── z_rep_translation.fasta
│ │ └── ...
│ └── self_score_folder
│ ├── blast_results_x.tsv
│ ├── blast_results_y.tsv
│ ├── blast_results_z.tsv
│ └── ...
├── hashes_dna_matches.tsv
├── hashes_prot_matches.tsv
├── reps_vs_reps_matches.tsv
├── reps_vs_alleles_matches.tsv
├── unmatched.tsv
└── Match_Schemas_Results.tsv
Report files description
Query |
Subject |
BSR |
Process |
|---|---|---|---|
x |
y |
1.0 |
hashes_dna |
z |
a |
1.0 |
hashes_prot |
b |
c |
0.765 |
rep_vs_rep |
d |
Not Matched |
NA |
rep_vs_rep |
Not Matched |
e |
NA |
rep_vs_alleles |
… |
Columns description:
Query: The loci from the query schema.
Subject: The best loci matches from the subject schema.
BSR: The BSR value for the best match.
Process: From which type of comparison is this match from.
This final file is the result of merging several temporary files: hashes_dna_matches.tsv, hashes_prot_matches.tsv, reps_vs_reps_matches.tsv and reps_vs_alleles_matches.tsv. In the matches determined based on sequence hash comparison, the BSR value is set to 1.0 as the sequences match exactly. A locus from the Query schema can have more than one matche with loci in the Subject schema. Each Subject locus only appears once with the best Query match. This file can be used as input to the SchemaAnnotation module when using the match_schemas option.
Examples
Here are some example commands to use the MatchSchemas module:
# Match schemas using default parameters
SR MatchSchemas -fs /path/to/first_schema -ss /path/to/second_schema -o /path/to/output_folder
# Match schemas with custom parameters
SR MatchSchemas -fs /path/to/first_schema -ss /path/to/second_schema -o /path/to/output_folder -ra True -c 4 -b 0.7 -tt 4 --nocleanup
Troubleshooting
If you encounter issues while using the MatchSchemas module, consider the following troubleshooting tips:
Verify that the paths to the query and subject schema directories are correct.
Check the output directory for any error logs or messages.
Increase the number of CPUs using the -c or –cpu option if the process is slow.
If it is a BLAST database related error, try deleting the BLAST folders in the output and run the command again and run the schema through the AdaptLoci as it checks for loci name conflicts.